-
Apache Kafka카테고리 없음 2019. 5. 12. 13:20
소개

Kafka는 분산 messaging platform으로 publisher/subscriber model을 기반으로 동작한다. 분산 플랫폼이므로 실시간 대용량 로그 처리에 용이하다.producer가 특정 topic의 message들을 생성하면 Kafka cluster가 각 topic별로 분류하여 보관한다. 그리고 각 topic을 구독하고있는 consumer들이 해당 topic의 message들을 가져가는 형태이다.
Topic

Topic은 여러 partition들로 쪼개져 Kafka cluster의 각 서버에 저장된다. 이 때 각 partition별로 메세지의 순서가 보장된다. Replication(복제) 설정을 해두면, 마찬가지로 각 cluster의 각 서버에 partition별로 복제되어 저장되고, 특정 partition이 장애가 발생하면 복제된 partition으로 failover한다.
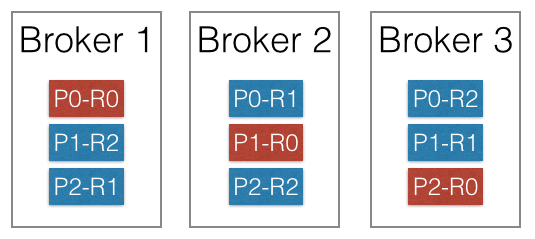
복제 factor가 3인 cluster
위 그림처럼 복제 설정이 되어 있으면, 각 partition마다 각 broker에서 하나가 leader가 된다. 위의 그림에서 붉은 색 partition이 leader이고 푸른 색이 follower이다. 모든 read/write는 leader에게 이루어지고, follower는 단순히 leader를 복제한다. 그리고 leader가 장애가 생기면 follower 중 하나가 다시 leader가 되는 방식이다.
Consumer Group

Kafka는 Consumer Group이라는 개념을 도입해 consumer들을 관리한다. 각 Consumer Group의 consumer들은 각각 다른 partition에서 메세지를 읽어온다. 즉, 각 consumer는 특정 partition의 owner가 된다. 물론 위의 그림에서 Consumer Group A의 경우에는, partition의 개수(4개)보다 consumer 수(2개)가 더 적기 때문에, 각 consumer가 2개의 partition의 owner가 된다. 반대로, partition의 수보다 consumer의 수가 더 많으면, 특정 consumer는 처리할 partition이 없어지므로 분산 처리 효과가 줄어든다.
따라서, 위와 같은 분산 처리가 잘 이루어지려면 consumer의 수와 partition의 수가 적절히 균형을 이루고 있어야한다. 또한, 각 partition의 메세지는 순서가 보장되지만, 서로 다른 partition에 있는 것들은 순서가 보장되지 않기 때문에 모든 순서가 중요한 topic의 경우에는 partition을 하나로 설정해야 한다. ex. P0에 있는 message들은 순차적으로 읽어지지만, P0와 P3 사이에는 순서가 없다.
File System Design
Kafka의 특징은 기존 메시징 시스템(ex. RabbitMQ)과 달리 메시지를 메모리에 저장해두지 않고, file system에 저장한다. 그러나, Kafka는 높은 throughput이 특징이다. 따라서, file system을 사용하는데 memory를 사용한 것보다 더 좋은 성능을 낼 수 있는 것이 어떻게 가능한지 의문이 생긴다.

우선, Kafka에서 메세지는 순차적으로 저장되기 때문에, disk 순차 접근이라 랜덤 접근 때보다 더 좋은 성능을 낸다. 그러나, 위 표에서 볼 수 있듯이, 그럼에도 불구하고 순차 메모리 접근보다 순차 디스크 접근이 약 7배 정도 느리다. Kafka는 이러한 느린 속도를 다음과 같은 방식으로 해결했다.
1. OS 캐시 사용
Kafka는 메모리에 cache를 별도로 구현한 것이 아니라 OS의 페이지 캐시를 사용한다. 따라서, OS가 알아서 서버의 남은 memory를 페이지 캐시로 활용하고, 순차 접근이기 때문에 사용될 것으로 예상되는 페이지들을 미리 캐싱해둔다.(read ahead) 또한, Kafka process가 캐시를 관리하는 것이 아니고 OS가 관리하므로, process를 재시작 하더라도 캐시가 그대로 남아있을 수 있다.
2. 메세지를 네트워크를 통해 consumer에게 전달할 때 zero-copy 기법을 사용했다.

전통적인 방식
전통적인 방식
일반적으로는 디스크에서 파일을 읽어오고 어플리케이션 버퍼에 저장해둔 다음에 다시 네트워크를 타고 전달된다. 이러한 방식은 User mode와 Kernel mode를 왔다갔다 하므로 mode switching이 빈번히 발생하고, 불필요한 data copy가 발생한다.

zero-copy 방식
그러나 Kafka는 Kernel mode에서 바로 disk read buffer에서 socket buffer로 data를 전송하는 zero-copy 방식을 사용해 성능을 개선했다.
기존 메세징 시스템과의 차이
1. 분산 시스템 기반으로, 분산 및 복제가 용이하다.
2. AMQP 프로토콜을 사용하지 않고, 단순한 메세지 헤더를 가진 TCP 프로토콜을 사용하여 프로토콜에 의한 오버헤드를 줄였다.
3. producer가 여러 메세지를 broker에 전달할 때 하나씩 보내던 것과 달리, Kafka는 여러 메세지를 묶어서 batch형태로 한 번에 전달할 수 있다.
4. 메세지를 메모리에 저장하지 않고 파일 시스템에 저장한다.
- 기존 메세징 시스템에서는 메모리에 메세지를 저장하기 때문에, 메세지의 수가 많아지면 성능이 감소하였다. 그러나, 파일 시스템을 사용하면 메세지의 수가 많아져도 성능이 별로 감소하지않는다.
- consumer가 소비한 메세지를 바로 삭제하는 기존 시스템과 달리, Kafka는 설정해 둔 시간만큼 메세지를 남겨둔다. 따라서, consumer가 이전 메세지들을 다시 읽을 수 있다.
5. 기존 메시징 시스템은 broker가 consumer에게 메시지를 push하는 방식이었으나, Kafka는 consumer가 broker에 pull하는 방식이다.
→ push 방식은 broker가 모든 consumer들의 상태 정보(어떤 메세지를 처리해야하는지)를 트랙킹하고 있어야했다. 하지만, Kafka의 pull 방식은 consumer가 message offset을 저장해두고 알아서 pull하는 방식이므로 부담이 덜하고, 메세지를 쌓아두었다가 batch로 처리하는 구현이 가능하다.
기존 메세징 시스템과의 성능 비교
1. Producer 성능

2. Consumer 성능
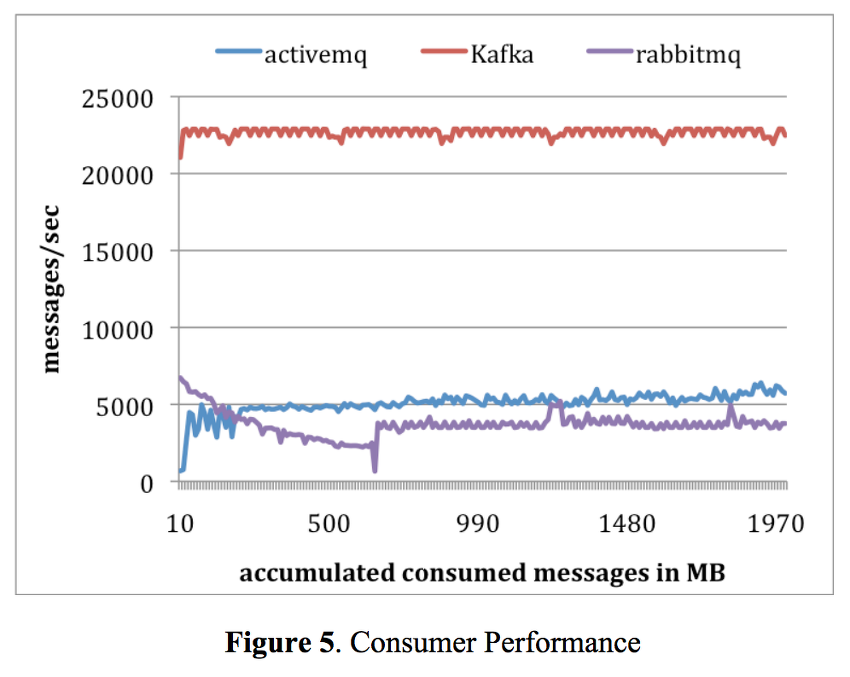
참고
https://kafka.apache.org/documentation/