-
Spring Webflux + Reactorspring 2019. 5. 13. 14:17
Spring 5 개요

스프링5는 내부적으로 스프링 부트2를 사용하며, web stack은 2가지로 구성되어 있다. 기존처럼 서블릿 구조를 사용하는 Spring MVC stack과 스프링5부터 새롭게 도입된 Reactive stack인 Spring Webflux 스택으로 이루어져 있다. 위 그림에서 볼 수 있듯이, Reactive stack인 경우에는 Reactor가 필수이고, Netty와 같은 비동기/non-blocking 모델의 네트워킹 프레임워크를 사용한다. 물론 Reactive stack에서도 Tomcat, Jetty와 같은 서블릿 기반의 컨테이너를 사용할 수 있지만, 이 경우에는 Servlet 3.1 non-blocking I/O를 사용한다. webflux도 비동기/non-blocking 모델이기 때문에, DB I/O시 block이 걸리지 않도록 하기 위해 몽고db와 같은 reactive DB를 지원한다. 두 개의 web stack 중 MVC를 사용할지, Webflux를 사용할지 선택하면 된다.

Spring MVC에서 Spring Webflux로
스프링 MVC에서 스프링 Webflux로 넘어가면서 서블릿 구조의 멀티스레드에서 이벤트 기반 리액티브 프로그래밍으로 패러다임이 전환된다. 이벤트 기반 리액티브 프로그래밍으로 가면서 스레드의 수는 1 클라이언트당 하나씩 생성되는 구조가 아니라, 연결을 수락하는 하나의 보스 스레드와 cpu의 코어 수에 비례하는 N개의 워커 스레드만으로 구성된다. node나 netty의 구조와 동일하다. 이러한 전환은 결국 멀티스레드 모델의 근본적인 한계(동시 접속자가 많으면 메모리 부족 -> 성능 저하)에서 비롯된다.
스프링 Webflux는 디폴트로 네티를 사용하여 네트워킹을 한다. 앞서 언급했던 대로, 네티는 채널 연결을 관리하는 보스 스레드 1개와 N개의 워커 스레드(reactor-netty의 경우 디폴트로, CPU 코어 수)로 구성되어 있는데, 이렇기 때문에 하나의 워커 스레드가 block이 오래 걸리면 클라이언트의 요청을 원활히 수행할 수가 없게 된다. 그렇다고 워커 스레드에서 또 다른 thread를 매 번 생성한다면 기존 멀티 스레드 모델보다 오히려 더 많은 스레드가 필요하게 된다. 때문에 자연스럽게, 워커 스레드에서 수행하는 작업들을 non-blocking/asynchronous하게 처리할 필요가 있다. 그렇기 때문에 스프링 Webflux에 Project Reactor라는 리액티브 스택이 기본으로 추가되어 있다.
[참고]
webflux 프레임워크에 서블릿 컨테이너를 이용하면 더 많은 스레드를 사용한다(톰캣의 경우 10개). 이는 blocking I/O와 non-blocking I/O를 모두 지원하기 위함이다.
Reactive란?
"reactive"는 변화에 반응하도록 설계된 프로그래밍 모델을 가리킨다. I/O 이벤트에 반응하는 네트워크 컴포넌트, 마우스 이벤트에 반응하는 UI controller 등을 예로 들 수 있다. 그러한 의미에서 non-blocking도 동작이 완료되면 알림을 주는 것에 반응하는 것이므로 reactive이다.
Spring에서 reactive라는 용어는 non-blocking back pressure의 의미로 연관된다. blocking 모델에서는 모든 데이터가 준비될 때까지 기다려야한다면, non-blocking 코드에서는 소비자가 생산자의 데이터의 속도를 컨트롤할 수 있다는 점(back pressure)에서 중요한 특징을 갖는다. 소비자의 소비 속도에 비해 생산자가 너무 빠르게 데이터를 생산해낸다면 그 양을 조절해가며 요청할 수 있다. 반대의 경우도 마찬가지이다.
스프링 webflux에서 사용하는 Reactor는 Reactive Streams라는 표준 스펙을 따른다. Reactor의 기본적인 내용들을 잠시 소개하고자 한다.
Flux와 Mono
Reactor에서 사용하는 publisher에는 Flux와 Mono가 있다. Flux는 0부터 N개의 데이터 스트림이다. Mono는 0부터 1개의 데이터 스트림이다.

Flux 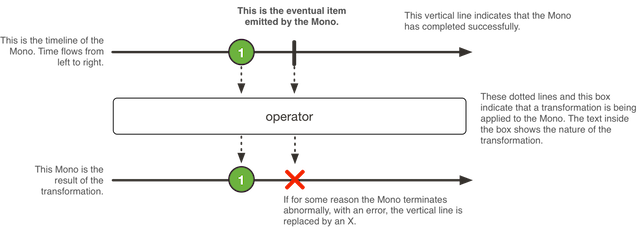
Mono Flux와 Mono가 Java의 Stream과 비슷한데, Flux와 Mono는 비동기로 데이터 스트림을 수행할 수 있다. 비동기로 수행할 수 있다는 말은 일반적으로는 동기로 수행하는데, publishOn(), subscribeOn()과 같은 메소드로 수행할 스레드를 지정할 수 있다는 말과 같다. publishOn()에서는 Subscriber의 onNext(), onComplete(), onError()를 실행할 Publisher의 스레드를 지정한다. subscribeOn()에서는 Publisher의 subsribe()와 자신의 onSubscribe()를 호출할 Subscriber의 스레드를 지정한다.
( Reactive Streams의 표준 publisher/subscriber 구조를 이해할 필요가 있다.)
Reactor는 Schedulers 클래스를 이용하여 작업을 처리할 스레드를 제공한다. 아래는 예제 코드이다.
Flux.just(1, 2, 3) .publishOn(Schedulers.newSingle("PUB")) .map(item -> item * 10) .log() .subscribeOn(Schedulers.newSingle("SUB")) .subscribe(item -> System.out.println(Thread.currentThread().getName() + ": " + item));결과는 아래와 같다.
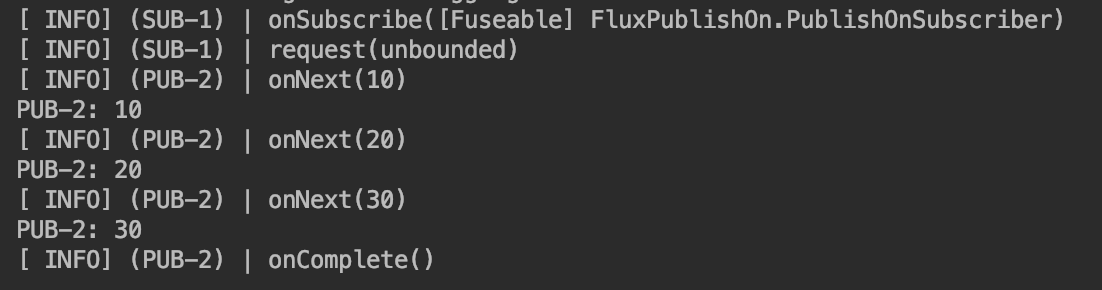
subscribe()메소드의 파라미터로 onNext()메소드를 Consumer형태로 구현한 간단한 subscriber를 전달하였다. 로그를 보면 subscribe() 메소드 파라미터로 전달한 람다식의 스레드가 onNext()이며, publishOn()으로 지정한 publisher 스레드가 메소드를 수행한 것을 확인할 수 있다. 그리고 subscribeOn()에서 지정한 subscriber 스레드가 onSubscribe(), request()를 호출한 것을 알 수 있다. (request(unbounded)는 개수 제한 없이 모든 데이터를 emit할 것을 요구하는 것이다.)
위에서 볼 수 있듯이 Flux와 Mono는 비동기 데이터 스트림을 구성할 수 있다는 점에서 기존 Java의 Stream과는 가장 큰 차이를 보인다. 하지만 비동기로 구성할 수 있을 뿐이지 그것을 강제하고 있지는 않다. 위처럼 subscribeOn(), publishOn()과 같은 메소드를 사용하지 않는다면 일반적인 동기 데이터 스트림이 된다.
스프링 Webflux로 잠시 다시 돌아와서, 워커 스레드가 고정된 N개이므로 오랫동안 block이 되서는 안된다. CPU연산이 오래 걸리거나 I/O 블로킹 작업인 경우에는 비동기 데이터 스트림으로 작업을 처리할 필요가 있다. 이것이 Webflux가 리액티브 스택 위에서 구현되어야 하는 이유이다.
Schedulers
위의 예제에서 publisher와 subscriber의 스레드를 지정하기 위해 Schedulers 클래스를 사용하였다. Schedulers는 다음과 같은 static 메소드를 가지고 있다.
1. Schedulers.immediate(): 현재 스레드
2. Schedulers.single(): 단일의 재사용 가능한 스레드, 모든 호출자가 같은 스레드를 사용한다. 호출 때마다 새로운 스레드를 원한다면 Schedulers.newSingle()을 사용해야 한다.
3. Schedulers.elastic(): elastic한 스레드 풀, 필요한 만큼 새 스레드 풀을 생성하고, 놀고 있는 스레드를 재사용한다. 너무 오래(기본 값 60초) 놀고 있는 스레드 풀은 폐기된다. I/O 블록킹 작업을 할 때 좋은 선택이다.
4. Schedulers.parallel(): 병렬 작업을 하도록 튜닝이 된 고정 스레드 풀이다. CPU 코어 수 만큼의 워커 스레드를 생성한다. CPU-bound 블록킹 작업을 하기에 좋은 선택이다.
Schedulers.newXXX메소드를 통해 위의 기능들을 새로운 스케쥴러(새로운 스레드풀)로 돌아가게 할 수 있다.
참고: https://projectreactor.io/docs/core/release/reference/#schedulers
Reactor 3 Reference Guide
The Reactor project main artifact is reactor-core, a reactive library that focuses on the Reactive Streams specification and targets Java 8. Reactor introduces composable reactive types that implement Publisher but also provide a rich vocabulary of operato
projectreactor.io
Webflux Programming Models
Spring Webflux는 다음과 같은 2가지 프로그래밍 모델을 제공한다.
1. Annotated Controllers: Spring MVC처럼 annotation 기반의 모델이다. Spring MVC와 Webflux Controller 모두 reactive return type을 지원하기 때문에 큰 차이는 없다. 차이라고 한다면 Webflux는 reactive @RequestBody arguement를 지원한다.
ex.
@PostMapping("/person") Mono<Void> create(@RequestBody Publisher<Person> personStream) { return this.repository.save(personStream).then(); }2. Functional Endpoints: 람다식 기반, 경량의 함수형 프로그래밍 모델이다. request를 route하고 handle할 수 있도록 해준다.
ex.
import static org.springframework.http.MediaType.APPLICATION_JSON; import static org.springframework.web.reactive.function.server.RequestPredicates.*; PersonRepository repository = ... PersonHandler handler = new PersonHandler(repository); RouterFunction<ServerResponse> personRoute = route(GET("/person/{id}").and(accept(APPLICATION_JSON)), handler::getPerson) .andRoute(GET("/person").and(accept(APPLICATION_JSON)), handler::listPeople) .andRoute(POST("/person").and(contentType(APPLICATION_JSON)), handler::createPerson);Performance
reactive non-blocking이 일반적으로 애플리케이션을 더 빠르게 만들어주지는 않는다. 일부의 경우는 그렇지만 전반적으로는 더 많은 작업들을 요하고 때문에 처리 시간이 약간 증가된다.
reactive non-blocking의 핵심 장점은 적은 수의 고정된 스레드와 메모리로 스케일링할 수 있다는 점이다. 요청의 수가 많아지면 스레드의 수를 늘려야하는 기존 방식과 다르게 앞서 언급했던 대로 고정된 일부 스레드로 요청의 수의 변화에 대응할 수 있다.
참고
https://docs.spring.io/spring/docs/current/spring-framework-reference/web-reactive.html#webflux
https://projectreactor.io/docs/core/release/reference/index.html
'spring' 카테고리의 다른 글
Spring Webflux - Functional Endpoints (0) 2019.07.25 Spring Webflux - DispatcherHandler (0) 2019.07.18 Spring WebClient (0) 2019.07.10 Spring AMQP (0) 2019.05.13 JDK Dynamic Proxy vs CGLib Proxy (0) 2019.05.13